class: center, middle, inverse, title-slide # Data Wrangling and Visualisation in R ## Oxford IT Services ### <br> <br> ### 9 March 2020 --- layout: true <div class="my-footer"><span>https://justinmillar.github.io/ox-stats-r-workshop/</span></div> --- # Getting Started Have a (relatively recent) version of R and RStudio installed: - [Download R](https://www.r-project.org/) - [Download RStudio](https://rstudio.com/products/rstudio/download/) If you do not have `library(tidyverse)` installed, run the following: ```r "tidyverse" %in% rownames(installed.packages()) install.packages("tidyverse") ``` Follow slides at https://justinmillar.github.io/ox-stats-r-workshop/index.html Download [**notes**](https://justinmillar.github.io/ox-stats-r-workshop/notes.R) and [**exercises**](https://justinmillar.github.io/ox-stats-r-workshop/exercises.R) scripts. --- class: center # Introduction .pull-left[ <img class="circle" src="https://pbs.twimg.com/profile_images/1004462306820943872/XoWEuYZd_400x400.jpg" width="150px"/> ## Justin Millar [<svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M459.37 151.716c.325 4.548.325 9.097.325 13.645 0 138.72-105.583 298.558-298.558 298.558-59.452 0-114.68-17.219-161.137-47.106 8.447.974 16.568 1.299 25.34 1.299 49.055 0 94.213-16.568 130.274-44.832-46.132-.975-84.792-31.188-98.112-72.772 6.498.974 12.995 1.624 19.818 1.624 9.421 0 18.843-1.3 27.614-3.573-48.081-9.747-84.143-51.98-84.143-102.985v-1.299c13.969 7.797 30.214 12.67 47.431 13.319-28.264-18.843-46.781-51.005-46.781-87.391 0-19.492 5.197-37.36 14.294-52.954 51.655 63.675 129.3 105.258 216.365 109.807-1.624-7.797-2.599-15.918-2.599-24.04 0-57.828 46.782-104.934 104.934-104.934 30.213 0 57.502 12.67 76.67 33.137 23.715-4.548 46.456-13.32 66.599-25.34-7.798 24.366-24.366 44.833-46.132 57.827 21.117-2.273 41.584-8.122 60.426-16.243-14.292 20.791-32.161 39.308-52.628 54.253z"/></svg> @justinjmillar](http://twitter.com/justinjmillar) [<svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M476 3.2L12.5 270.6c-18.1 10.4-15.8 35.6 2.2 43.2L121 358.4l287.3-253.2c5.5-4.9 13.3 2.6 8.6 8.3L176 407v80.5c0 23.6 28.5 32.9 42.5 15.8L282 426l124.6 52.2c14.2 6 30.4-2.9 33-18.2l72-432C515 7.8 493.3-6.8 476 3.2z"/></svg> justin.millar@bdi.ox.ac.uk](mailto:justin.millar@bdi.ox.ac.uk) ] .pull-right[ <img class="circle" src="https://pbs.twimg.com/profile_images/903924164150652929/D9Uv-6Q5_400x400.jpg" width="150px"/> ## Andre Python [<svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M459.37 151.716c.325 4.548.325 9.097.325 13.645 0 138.72-105.583 298.558-298.558 298.558-59.452 0-114.68-17.219-161.137-47.106 8.447.974 16.568 1.299 25.34 1.299 49.055 0 94.213-16.568 130.274-44.832-46.132-.975-84.792-31.188-98.112-72.772 6.498.974 12.995 1.624 19.818 1.624 9.421 0 18.843-1.3 27.614-3.573-48.081-9.747-84.143-51.98-84.143-102.985v-1.299c13.969 7.797 30.214 12.67 47.431 13.319-28.264-18.843-46.781-51.005-46.781-87.391 0-19.492 5.197-37.36 14.294-52.954 51.655 63.675 129.3 105.258 216.365 109.807-1.624-7.797-2.599-15.918-2.599-24.04 0-57.828 46.782-104.934 104.934-104.934 30.213 0 57.502 12.67 76.67 33.137 23.715-4.548 46.456-13.32 66.599-25.34-7.798 24.366-24.366 44.833-46.132 57.827 21.117-2.273 41.584-8.122 60.426-16.243-14.292 20.791-32.161 39.308-52.628 54.253z"/></svg> @andrepython](http://twitter.com/https://twitter.com/andrepython) ] --- class: center, middle # RStudio 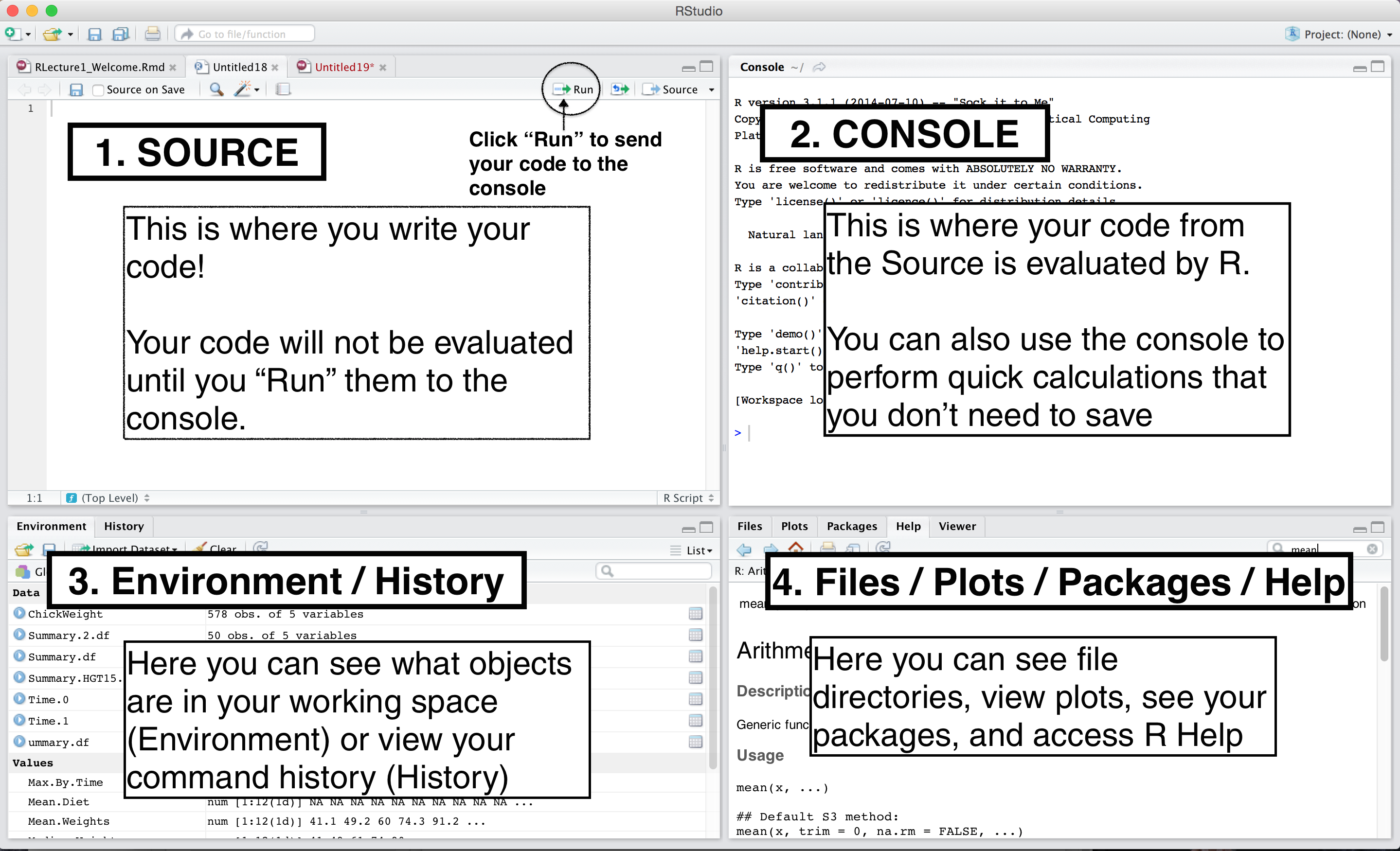 --- # R Projects RStudio projects keep all files used in an analysis (data files, R scripts, results, figures) in a single place A new folder will be created on your computer No longer need `setwd()`! Easy to share across computers: - Email folder or .zip - Use version control like Git --- class: center, middle <iframe src='https://gfycat.com/ifr/ImpureTerrificAllensbigearedbat' frameborder='0' hd='1' scrolling='no' allowfullscreen width='640' height='540'></iframe> --- background-image: url(https://www.tidyverse.org/images/tidyverse-default.png) background-position: 50% 50% class: center, bottom, inverse --- # Tidyverse .pull-left[ The "[`tidyverse`](https://www.tidyverse.org/)" is a collection of R packages that are specifically designed for data science, sharing a common design philosophy and grammar. These packages assume/enforce the use of ["tidy" data](https://vita.had.co.nz/papers/tidy-data.pdf): * Each variable must have it's own column * Each observation must have it's own row * Each value must have it's own cell .center[ <br> <a href="https://github.com/rfordatascience/tidytuesday"> <img src="https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/static/tt_logo.png" style="height:150px;"> </a> ] ] .pull-right[ .center[ <img src="http://www.seec.uct.ac.za/sites/default/files/image_tool/images/330/tidy_workflow.png" style="height:350px;"> ] ] --- # Load `tidyverse` and download data Once you have created your new R Project, start a new script and load the `tidyverse` library: ```r library(tidyverse) ``` For this workshop we will use a recent Tidy Tuesday dataset on from Spotify playlist. and download the data into your project folder: ```r # Download data file into project download.file( url = "https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-01-21/spotify_songs.csv", destfile = "spotify-data.csv") ``` You should now see `"spotify-data.csv"` in your project folder. --- # Loading data ```r spotify <- read_csv("spotify-data.csv") head(spotify) ``` --- class: center, middle, inverse .center[ <img src="https://raw.githubusercontent.com/rstudio/hex-stickers/master/PNG/dplyr.png" style="height:550px;"> ] --- # Data Wrangling with `dplyr` `dplyr` is the primary `tidyverse` package for data manipulation. Sometimes `dplyr` functions are called "verbs", which can be a helpful way of envision the "wrangling" steps. some common ones are: `select()` picks columns based on names `filter()` picks rows based on a condition `mutate()` adds a new variables that are functions of existing variables `summarise()` provides summarisations of specific variables (summary statistics) `group_by()` can be used with `summarise()` to group variables `distinct()` keep unique values --- # Using the "pipe" operator: `%>%` Typically data wrangle will involve multiple steps. Using base R operators this way usually requires saving intermediate objects or overwrite objects, which can be difficult to interpret, prone to typos/bugs, and poor use of memory. The pipe operator from the `magrittr` package (included in tidyverse), written as `%>%`, allows us to string data cleaning functions together by sending the output from the left-hand side of the pipe into the first argument in the right-hand side. Since the first argument of `dplyr` (most) functions is *always* our dataframe, this allows us to write code that is more human-readable and more computationally efficent. .pull-right[] --- class: split-40 count: false .column[.content[ ```r *spotify ``` ]] .column[.content[ ``` # A tibble: 32,833 x 23 track_id track_name track_artist track_popularity track_album_id <chr> <chr> <chr> <dbl> <chr> 1 6f807x0~ I Don't C~ Ed Sheeran 66 2oCs0DGTsRO98~ 2 0r7CVbZ~ Memories ~ Maroon 5 67 63rPSO264uRjW~ 3 1z1Hg7V~ All the T~ Zara Larsson 70 1HoSmj2eLcsrR~ 4 75Fpbth~ Call You ~ The Chainsm~ 60 1nqYsOef1yKKu~ 5 1e8PAfc~ Someone Y~ Lewis Capal~ 69 7m7vv9wlQ4i0L~ 6 7fvUMiy~ Beautiful~ Ed Sheeran 67 2yiy9cd2QktrN~ 7 2OAylPU~ Never Rea~ Katy Perry 62 7INHYSeusaFly~ 8 6b1RNvA~ Post Malo~ Sam Feldt 69 6703SRPsLkS4b~ 9 7bF6tCO~ Tough Lov~ Avicii 68 7CvAfGvq4RlIw~ 10 1IXGILk~ If I Can'~ Shawn Mendes 67 4QxzbfSsVryEQ~ # ... with 32,823 more rows, and 18 more variables: # track_album_name <chr>, track_album_release_date <chr>, # playlist_name <chr>, playlist_id <chr>, playlist_genre <chr>, # playlist_subgenre <chr>, danceability <dbl>, energy <dbl>, key <dbl>, # loudness <dbl>, mode <dbl>, speechiness <dbl>, acousticness <dbl>, # instrumentalness <dbl>, liveness <dbl>, valence <dbl>, tempo <dbl>, # duration_ms <dbl> ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% * select(track_artist, duration_ms) ``` ]] .column[.content[ ``` # A tibble: 32,833 x 2 track_artist duration_ms <chr> <dbl> 1 Ed Sheeran 194754 2 Maroon 5 162600 3 Zara Larsson 176616 4 The Chainsmokers 169093 5 Lewis Capaldi 189052 6 Ed Sheeran 163049 7 Katy Perry 187675 8 Sam Feldt 207619 9 Avicii 193187 10 Shawn Mendes 253040 # ... with 32,823 more rows ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% select(track_artist, duration_ms) %>% * mutate(duration_s = duration_ms / 1000) ``` ]] .column[.content[ ``` # A tibble: 32,833 x 3 track_artist duration_ms duration_s <chr> <dbl> <dbl> 1 Ed Sheeran 194754 195. 2 Maroon 5 162600 163. 3 Zara Larsson 176616 177. 4 The Chainsmokers 169093 169. 5 Lewis Capaldi 189052 189. 6 Ed Sheeran 163049 163. 7 Katy Perry 187675 188. 8 Sam Feldt 207619 208. 9 Avicii 193187 193. 10 Shawn Mendes 253040 253. # ... with 32,823 more rows ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% select(track_artist, duration_ms) %>% mutate(duration_s = duration_ms / 1000) %>% * filter(duration_s > 180) ``` ]] .column[.content[ ``` # A tibble: 26,523 x 3 track_artist duration_ms duration_s <chr> <dbl> <dbl> 1 Ed Sheeran 194754 195. 2 Lewis Capaldi 189052 189. 3 Katy Perry 187675 188. 4 Sam Feldt 207619 208. 5 Avicii 193187 193. 6 Shawn Mendes 253040 253. 7 Ed Sheeran 207894 208. 8 Ellie Goulding 203733 204. 9 Loud Luxury 192507 193. 10 Martin Garrix 255238 255. # ... with 26,513 more rows ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% select(track_artist, duration_ms) %>% mutate(duration_s = duration_ms / 1000) %>% filter(duration_s > 180) %>% * group_by(track_artist) ``` ]] .column[.content[ ``` # A tibble: 26,523 x 3 # Groups: track_artist [8,875] track_artist duration_ms duration_s <chr> <dbl> <dbl> 1 Ed Sheeran 194754 195. 2 Lewis Capaldi 189052 189. 3 Katy Perry 187675 188. 4 Sam Feldt 207619 208. 5 Avicii 193187 193. 6 Shawn Mendes 253040 253. 7 Ed Sheeran 207894 208. 8 Ellie Goulding 203733 204. 9 Loud Luxury 192507 193. 10 Martin Garrix 255238 255. # ... with 26,513 more rows ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% select(track_artist, duration_ms) %>% mutate(duration_s = duration_ms / 1000) %>% filter(duration_s > 180) %>% group_by(track_artist) %>% * count() ``` ]] .column[.content[ ``` # A tibble: 8,875 x 2 # Groups: track_artist [8,875] track_artist n <chr> <int> 1 'Til Tuesday 2 2 -M- 1 3 !!! 2 4 !deladap 3 5 "\"Dear Evan Hansen\" August 2018 Broadway Cast" 1 6 $uicideBoy$ 4 7 (G)I-DLE 1 8 (Sandy) Alex G 1 9 *NSYNC 3 10 [:SITD:] 4 # ... with 8,865 more rows ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% select(track_artist, duration_ms) %>% mutate(duration_s = duration_ms / 1000) %>% filter(duration_s > 180) %>% group_by(track_artist) %>% count() %>% * arrange(desc(n)) ``` ]] .column[.content[ ``` # A tibble: 8,875 x 2 # Groups: track_artist [8,875] track_artist n <chr> <int> 1 Martin Garrix 152 2 The Chainsmokers 111 3 Queen 102 4 Don Omar 99 5 David Guetta 96 6 Calvin Harris 90 7 Drake 77 8 Guns N' Roses 77 9 Kygo 77 10 The Weeknd 75 # ... with 8,865 more rows ``` ]] --- # Tidying data with `tidyr` The goal of tidyr is to help you create *tidy data*. some useful function we'll see are: .pull-left[ `separate()` separates one column into multiple `unite()` combines multiple columns into a single column ] .pull-right[ <img src="https://raw.githubusercontent.com/rstudio/hex-stickers/master/PNG/tidyr.png" style="height:350px;"> ] --- # Data visualization with `ggplot2` .pull-left[ .center[  ] ] .pull-right[ .center[ 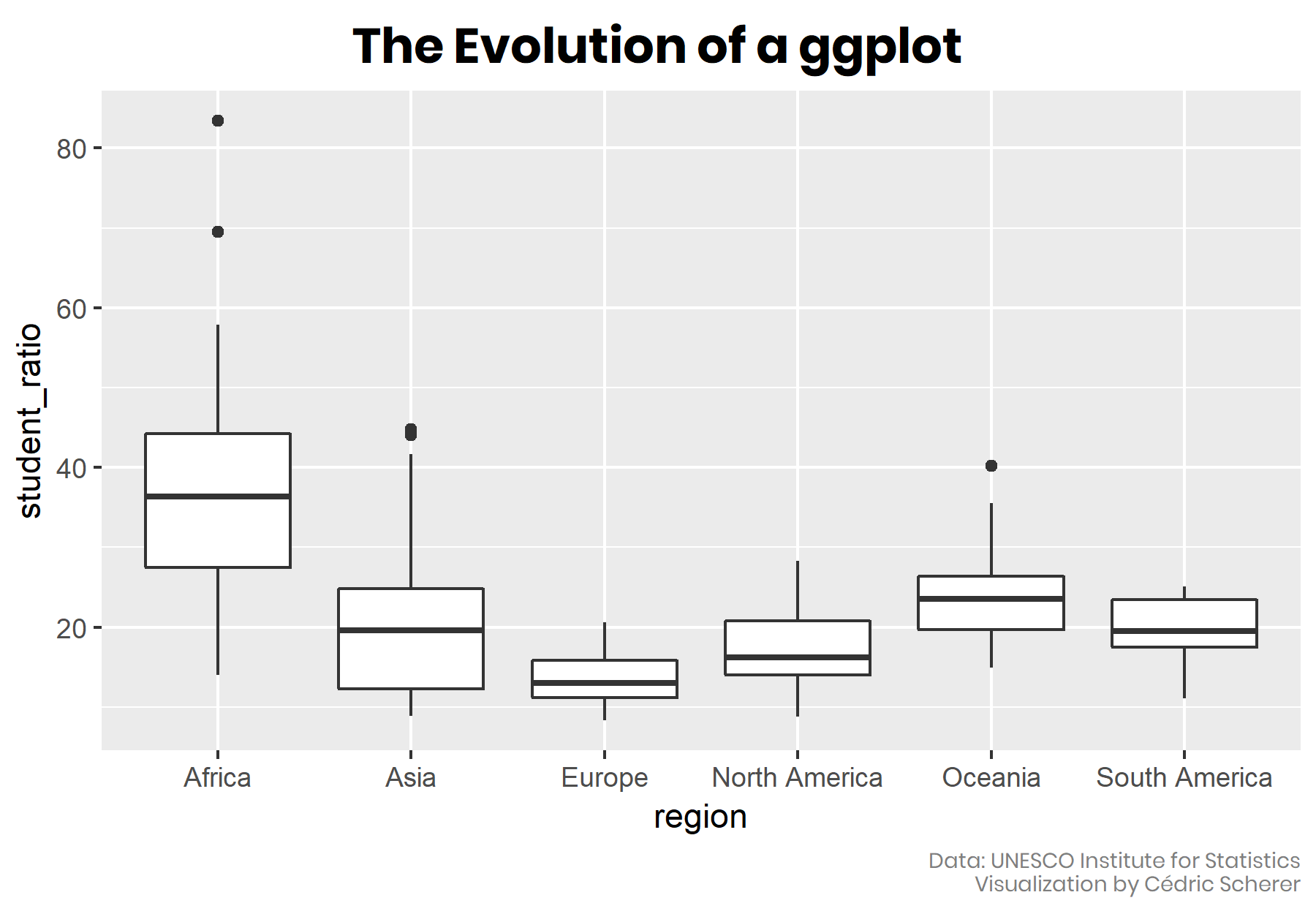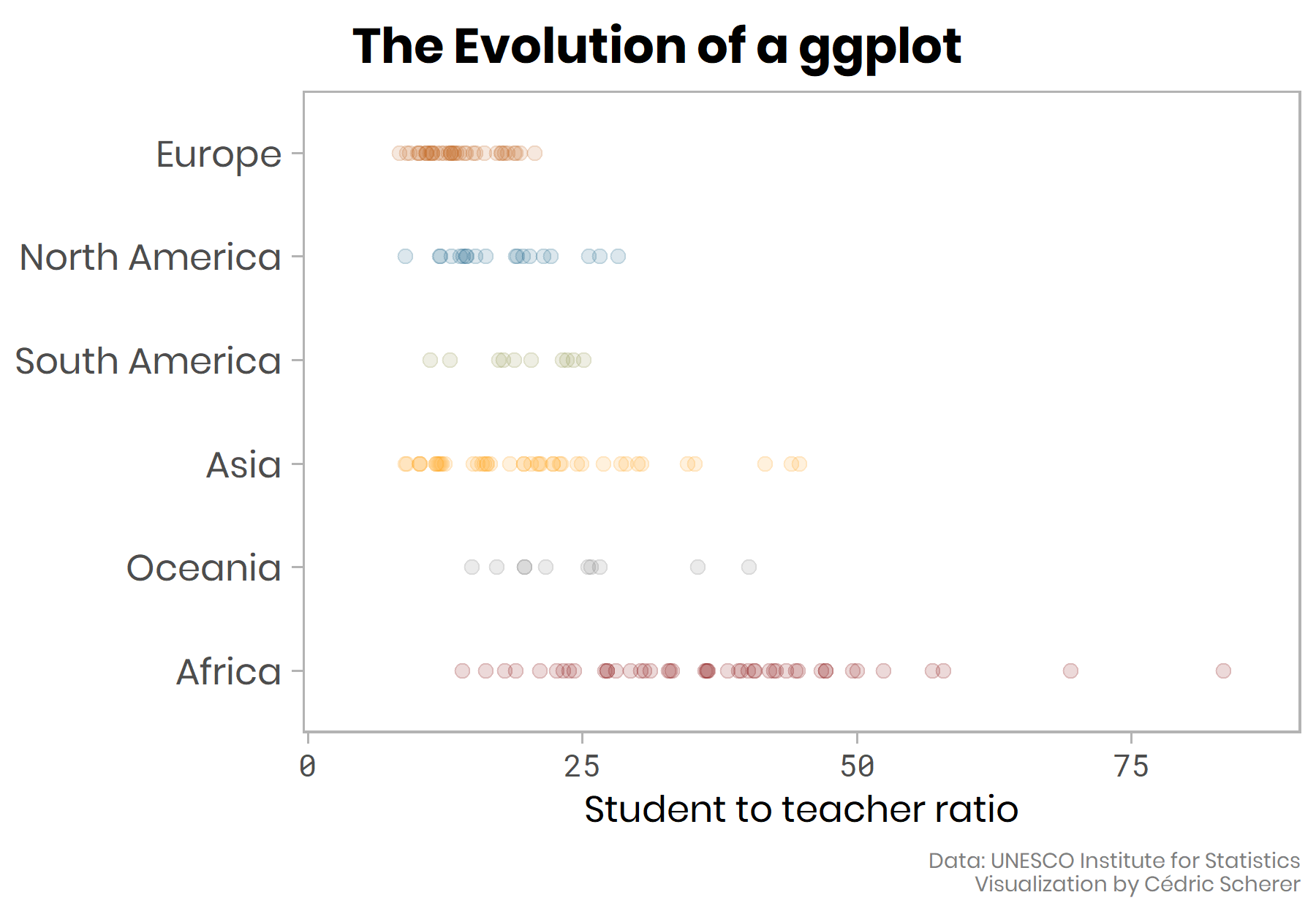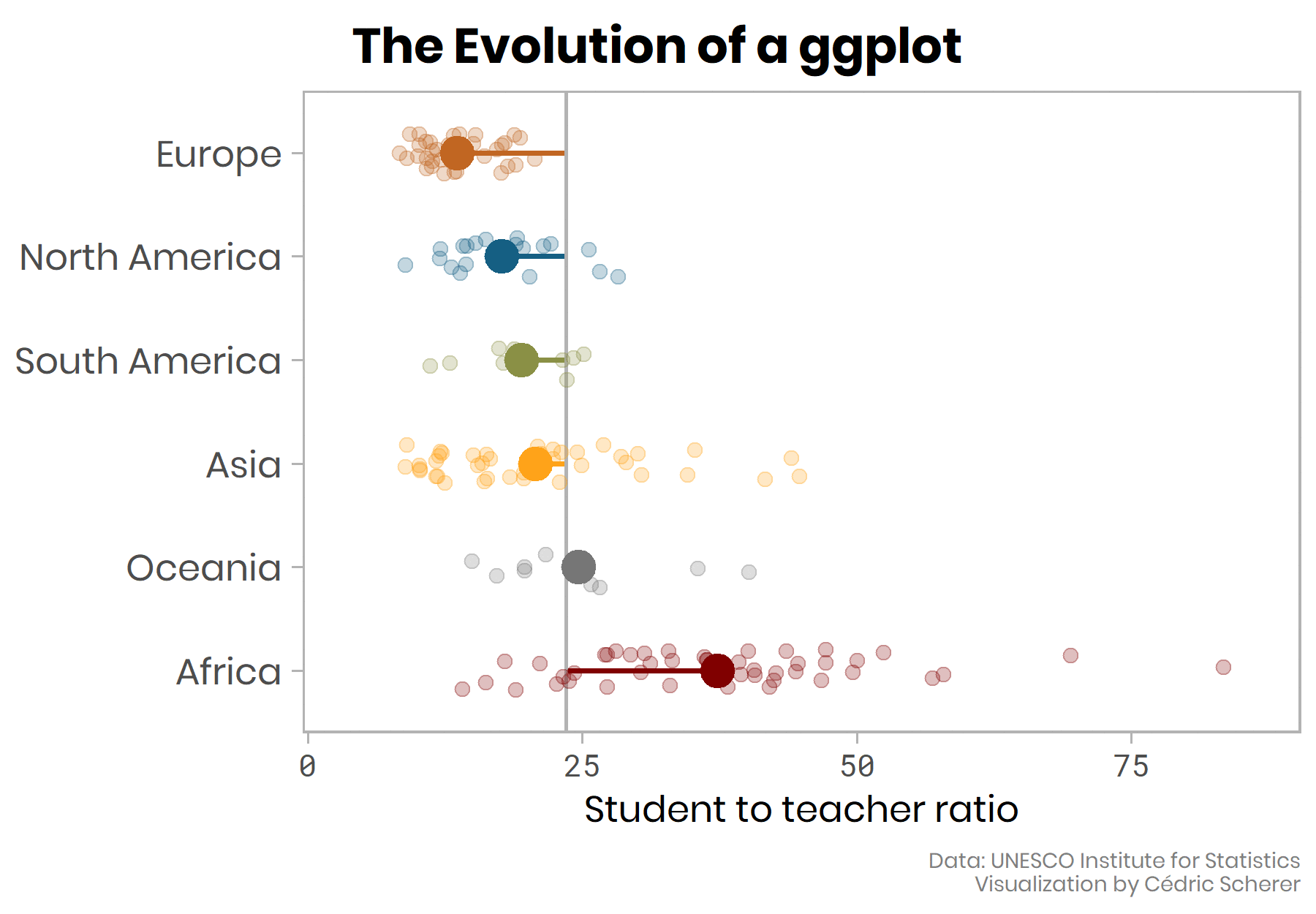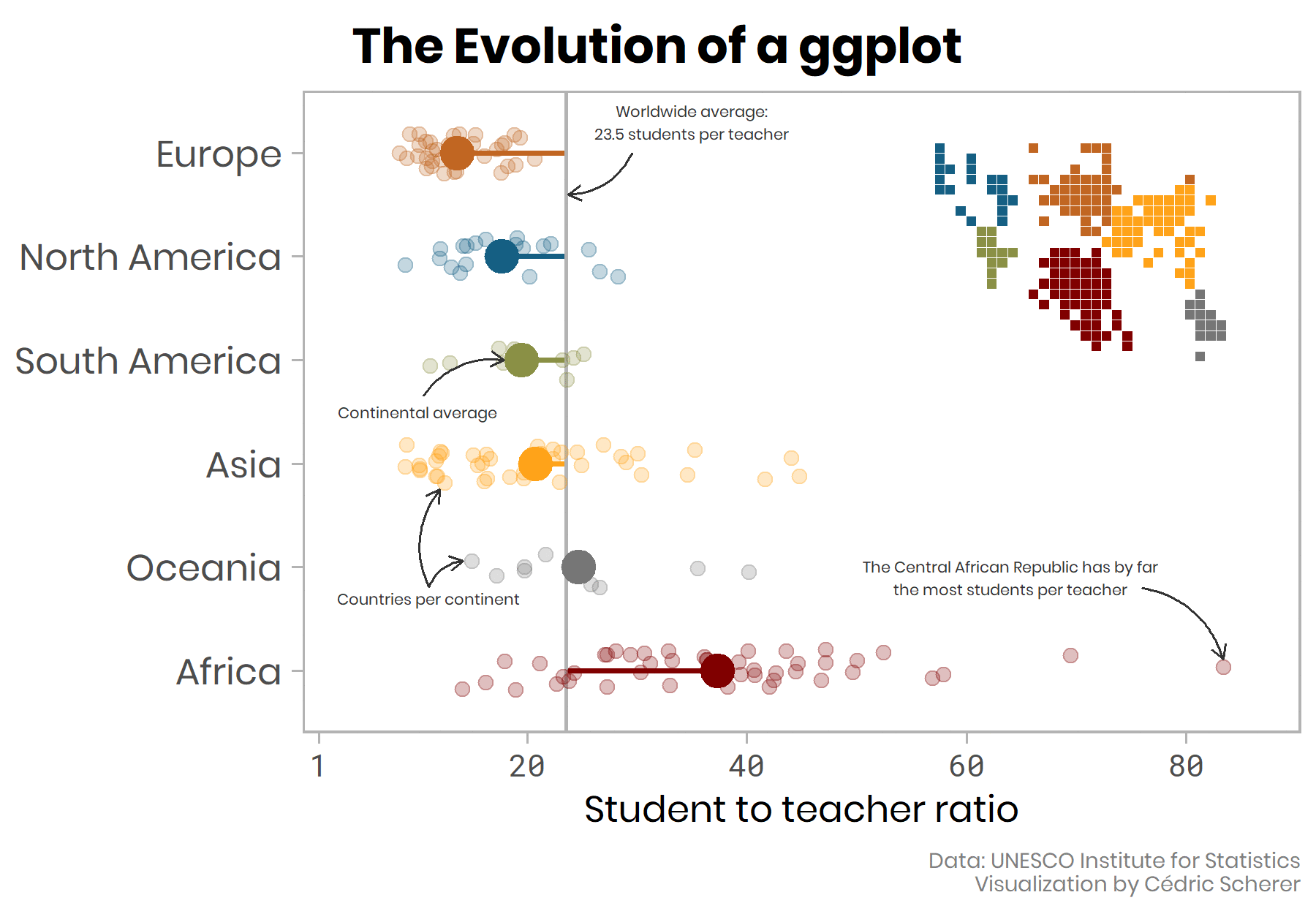 ] ] --- # Data visualization with `ggplot2` GG stands for *Graph of Grammar* Graphics are built step-by-step by adding new elements called `geom_()` Usually requires `data` and `mapping`, where `mapping` is defined using the `aes()` function. You provide characteristics here such as `x` and `y` variables. ```r ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM_FUNCTION>() ``` --- class: split-40 count: false .column[.content[ ```r *spotify ``` ]] .column[.content[ ``` # A tibble: 32,833 x 23 track_id track_name track_artist track_popularity track_album_id <chr> <chr> <chr> <dbl> <chr> 1 6f807x0~ I Don't C~ Ed Sheeran 66 2oCs0DGTsRO98~ 2 0r7CVbZ~ Memories ~ Maroon 5 67 63rPSO264uRjW~ 3 1z1Hg7V~ All the T~ Zara Larsson 70 1HoSmj2eLcsrR~ 4 75Fpbth~ Call You ~ The Chainsm~ 60 1nqYsOef1yKKu~ 5 1e8PAfc~ Someone Y~ Lewis Capal~ 69 7m7vv9wlQ4i0L~ 6 7fvUMiy~ Beautiful~ Ed Sheeran 67 2yiy9cd2QktrN~ 7 2OAylPU~ Never Rea~ Katy Perry 62 7INHYSeusaFly~ 8 6b1RNvA~ Post Malo~ Sam Feldt 69 6703SRPsLkS4b~ 9 7bF6tCO~ Tough Lov~ Avicii 68 7CvAfGvq4RlIw~ 10 1IXGILk~ If I Can'~ Shawn Mendes 67 4QxzbfSsVryEQ~ # ... with 32,823 more rows, and 18 more variables: # track_album_name <chr>, track_album_release_date <chr>, # playlist_name <chr>, playlist_id <chr>, playlist_genre <chr>, # playlist_subgenre <chr>, danceability <dbl>, energy <dbl>, key <dbl>, # loudness <dbl>, mode <dbl>, speechiness <dbl>, acousticness <dbl>, # instrumentalness <dbl>, liveness <dbl>, valence <dbl>, tempo <dbl>, # duration_ms <dbl> ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% * separate(col = track_album_release_date, * into = c("year", "month", "day"), * sep = "-") ``` ]] .column[.content[ ``` # A tibble: 32,833 x 25 track_id track_name track_artist track_popularity track_album_id <chr> <chr> <chr> <dbl> <chr> 1 6f807x0~ I Don't C~ Ed Sheeran 66 2oCs0DGTsRO98~ 2 0r7CVbZ~ Memories ~ Maroon 5 67 63rPSO264uRjW~ 3 1z1Hg7V~ All the T~ Zara Larsson 70 1HoSmj2eLcsrR~ 4 75Fpbth~ Call You ~ The Chainsm~ 60 1nqYsOef1yKKu~ 5 1e8PAfc~ Someone Y~ Lewis Capal~ 69 7m7vv9wlQ4i0L~ 6 7fvUMiy~ Beautiful~ Ed Sheeran 67 2yiy9cd2QktrN~ 7 2OAylPU~ Never Rea~ Katy Perry 62 7INHYSeusaFly~ 8 6b1RNvA~ Post Malo~ Sam Feldt 69 6703SRPsLkS4b~ 9 7bF6tCO~ Tough Lov~ Avicii 68 7CvAfGvq4RlIw~ 10 1IXGILk~ If I Can'~ Shawn Mendes 67 4QxzbfSsVryEQ~ # ... with 32,823 more rows, and 20 more variables: # track_album_name <chr>, year <chr>, month <chr>, day <chr>, # playlist_name <chr>, playlist_id <chr>, playlist_genre <chr>, # playlist_subgenre <chr>, danceability <dbl>, energy <dbl>, key <dbl>, # loudness <dbl>, mode <dbl>, speechiness <dbl>, acousticness <dbl>, # instrumentalness <dbl>, liveness <dbl>, valence <dbl>, tempo <dbl>, # duration_ms <dbl> ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% * filter(year >= 1980 & !is.na(year)) ``` ]] .column[.content[ ``` # A tibble: 31,692 x 25 track_id track_name track_artist track_popularity track_album_id <chr> <chr> <chr> <dbl> <chr> 1 6f807x0~ I Don't C~ Ed Sheeran 66 2oCs0DGTsRO98~ 2 0r7CVbZ~ Memories ~ Maroon 5 67 63rPSO264uRjW~ 3 1z1Hg7V~ All the T~ Zara Larsson 70 1HoSmj2eLcsrR~ 4 75Fpbth~ Call You ~ The Chainsm~ 60 1nqYsOef1yKKu~ 5 1e8PAfc~ Someone Y~ Lewis Capal~ 69 7m7vv9wlQ4i0L~ 6 7fvUMiy~ Beautiful~ Ed Sheeran 67 2yiy9cd2QktrN~ 7 2OAylPU~ Never Rea~ Katy Perry 62 7INHYSeusaFly~ 8 6b1RNvA~ Post Malo~ Sam Feldt 69 6703SRPsLkS4b~ 9 7bF6tCO~ Tough Lov~ Avicii 68 7CvAfGvq4RlIw~ 10 1IXGILk~ If I Can'~ Shawn Mendes 67 4QxzbfSsVryEQ~ # ... with 31,682 more rows, and 20 more variables: # track_album_name <chr>, year <chr>, month <chr>, day <chr>, # playlist_name <chr>, playlist_id <chr>, playlist_genre <chr>, # playlist_subgenre <chr>, danceability <dbl>, energy <dbl>, key <dbl>, # loudness <dbl>, mode <dbl>, speechiness <dbl>, acousticness <dbl>, # instrumentalness <dbl>, liveness <dbl>, valence <dbl>, tempo <dbl>, # duration_ms <dbl> ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% * mutate(duration_min = duration_ms/60000) ``` ]] .column[.content[ ``` # A tibble: 31,692 x 26 track_id track_name track_artist track_popularity track_album_id <chr> <chr> <chr> <dbl> <chr> 1 6f807x0~ I Don't C~ Ed Sheeran 66 2oCs0DGTsRO98~ 2 0r7CVbZ~ Memories ~ Maroon 5 67 63rPSO264uRjW~ 3 1z1Hg7V~ All the T~ Zara Larsson 70 1HoSmj2eLcsrR~ 4 75Fpbth~ Call You ~ The Chainsm~ 60 1nqYsOef1yKKu~ 5 1e8PAfc~ Someone Y~ Lewis Capal~ 69 7m7vv9wlQ4i0L~ 6 7fvUMiy~ Beautiful~ Ed Sheeran 67 2yiy9cd2QktrN~ 7 2OAylPU~ Never Rea~ Katy Perry 62 7INHYSeusaFly~ 8 6b1RNvA~ Post Malo~ Sam Feldt 69 6703SRPsLkS4b~ 9 7bF6tCO~ Tough Lov~ Avicii 68 7CvAfGvq4RlIw~ 10 1IXGILk~ If I Can'~ Shawn Mendes 67 4QxzbfSsVryEQ~ # ... with 31,682 more rows, and 21 more variables: # track_album_name <chr>, year <chr>, month <chr>, day <chr>, # playlist_name <chr>, playlist_id <chr>, playlist_genre <chr>, # playlist_subgenre <chr>, danceability <dbl>, energy <dbl>, key <dbl>, # loudness <dbl>, mode <dbl>, speechiness <dbl>, acousticness <dbl>, # instrumentalness <dbl>, liveness <dbl>, valence <dbl>, tempo <dbl>, # duration_ms <dbl>, duration_min <dbl> ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% * select(year, duration_min, playlist_genre) ``` ]] .column[.content[ ``` # A tibble: 31,692 x 3 year duration_min playlist_genre <chr> <dbl> <chr> 1 2019 3.25 pop 2 2019 2.71 pop 3 2019 2.94 pop 4 2019 2.82 pop 5 2019 3.15 pop 6 2019 2.72 pop 7 2019 3.13 pop 8 2019 3.46 pop 9 2019 3.22 pop 10 2019 4.22 pop # ... with 31,682 more rows ``` ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% * ggplot() ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_6_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + * aes(x=year, y = duration_min, color = playlist_genre) ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_7_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + * geom_jitter(alpha = 0.3) ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_8_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + geom_jitter(alpha = 0.3) + * labs(x = "Year", y = "Duration in minutes", color = "Genre") ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_9_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + geom_jitter(alpha = 0.3) + labs(x = "Year", y = "Duration in minutes", color = "Genre") + * scale_x_discrete(breaks = seq(1980, 2020, 10)) ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_10_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + geom_jitter(alpha = 0.3) + labs(x = "Year", y = "Duration in minutes", color = "Genre") + scale_x_discrete(breaks = seq(1980, 2020, 10)) + * scale_color_viridis_d(option = "magma") ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_11_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + geom_jitter(alpha = 0.3) + labs(x = "Year", y = "Duration in minutes", color = "Genre") + scale_x_discrete(breaks = seq(1980, 2020, 10)) + scale_color_viridis_d(option = "magma") + * theme_bw() ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_12_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + geom_jitter(alpha = 0.3) + labs(x = "Year", y = "Duration in minutes", color = "Genre") + scale_x_discrete(breaks = seq(1980, 2020, 10)) + scale_color_viridis_d(option = "magma") + theme_bw() + * facet_wrap(~playlist_genre) ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_13_output-1.png" width="432" /> ]] --- class: split-40 count: false .column[.content[ ```r spotify %>% separate(col = track_album_release_date, into = c("year", "month", "day"), sep = "-") %>% filter(year >= 1980 & !is.na(year)) %>% mutate(duration_min = duration_ms/60000) %>% select(year, duration_min, playlist_genre) %>% ggplot() + aes(x=year, y = duration_min, color = playlist_genre) + geom_jitter(alpha = 0.3) + labs(x = "Year", y = "Duration in minutes", color = "Genre") + scale_x_discrete(breaks = seq(1980, 2020, 10)) + scale_color_viridis_d(option = "magma") + theme_bw() + facet_wrap(~playlist_genre) + * theme(legend.position = "none") ``` ]] .column[.content[ <img src="index_files/figure-html/pipe-ggplot_auto_14_output-1.png" width="432" /> ]] --- ### From here we are going to begin some live coding ### please open `notes.R` --- # Helpful links - [Cheatsheets](https://rstudio.com/resources/cheatsheets/): [RStudio IDE](https://github.com/rstudio/cheatsheets/raw/master/rstudio-ide.pdf) | [dplyr](https://github.com/rstudio/cheatsheets/raw/master/data-transformation.pdf) | [ggplot](https://github.com/rstudio/cheatsheets/raw/master/data-visualization-2.1.pdf) - [R for Data Science](https://r4ds.had.co.nz/) - [Tidy Tuesday GitHub](https://github.com/rfordatascience/tidytuesday)